Appearance
How I trust what an AI builds
An agent hands me a finished feature. The code reads well. The tests are green. The PR is tidy. And I still have no idea whether the thing actually works.
That gap is the whole problem. Agents write all the code in this project now, and they write it fast. So the bottleneck was never going to be whether the machine can build something. The bottleneck is me, on my phone, deciding whether to trust what came back.
Here's what I've learned: relying on reading the code to trust it doesn't scale, not at the volume an agent produces. So instead, I'm moving towards trusting the proof.
And the proof isn't the code. It's the artifact sitting above it: the feature actually running, the screenshot of the screen, the PR that says what changed and why. I review the result, not the diff. I'm not the first to land here:
I don't read changes in the code. I read changes in the artifacts.
The code is the agent's, the way it belongs to the engineers in any company and not the CEO. My job is the layer on top.
That layer on top is a stack of automated checks, and it all runs before I ever look. Most of the ways an agent can be wrong get caught by a machine long before I do. The last piece, and the one that took longest to get right, is visual regression. This post walks that whole net layer by layer, building to the piece I most recently cracked.
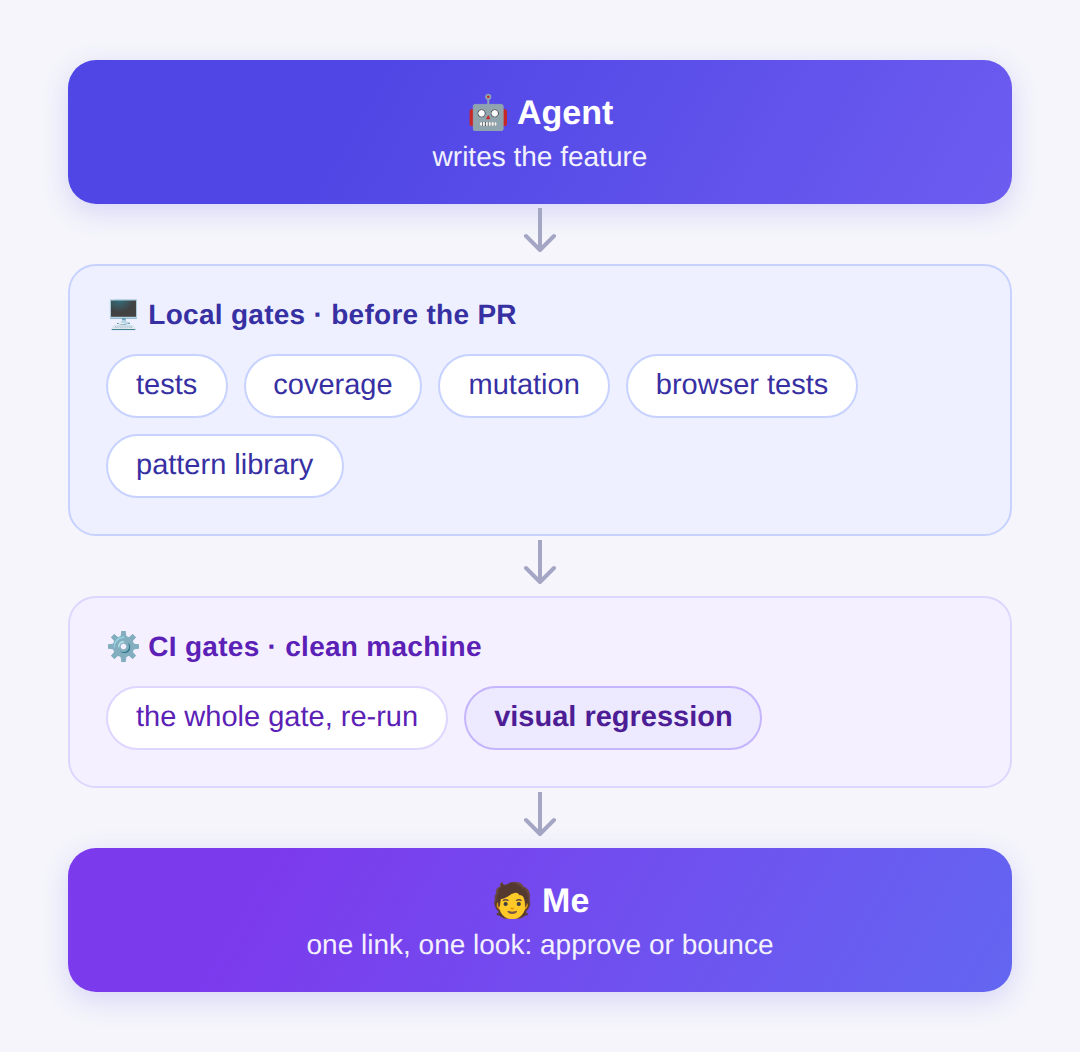
The workflow at a glance
Every change walks the same path. Most of it happens without me:
| # | Stage | Done by |
|---|---|---|
| 1 | Build the feature | 🤖 AI |
| 2 | Review its own code, run the local checks: Pest tests, coverage, mutation, browser tests | 🤖 AI |
| 3 | Open the PR with a readable title and body | 🤖 AI |
| 4 | Re-run the whole gate on a clean machine | ⚙️ CI |
| 5 | Screenshot every UI state at phone + desktop width, diff against the right baseline, publish the report to Cloudflare, tag the PR | ⚙️ CI |
| 6 | Open one link on a phone, then approve or bounce | 🧑 Me |
By the time anything reaches me, it has already been tested, measured, mutated, and screenshotted. Stage six is the only part that needs a human. The entire design goal is to keep shrinking it.
The bottleneck moved
Agents build fast. Getting working code back from one is no longer the hard part. The bottleneck has moved. It moved onto me, the person who has to decide whether what came back is any good.
And bottlenecks have a habit: whatever you make cheaper, you do more of. When review is expensive, you ration it. You skim the diff, decide the code looks right, and merge on faith. Each bit of friction is a small tax, and paid enough times it quietly lowers the bar.
So I'm really chasing two things, and the whole system is built around them:
The two jobs
- Catch as much as possible automatically, so less needs a human at all.
- Make the bit that's left seamless, so easy it gets done every time, even from a phone.
The long-term bet is that the first job keeps eating into the second. Stack enough proof below the human line, and what reaches me is only the part that genuinely needs judgement.
The net that catches it before I look
Most of trust isn't the human look. It's everything that runs before it. Each layer guards a different way for things to go wrong, and together they mean an agent's mistakes mostly get caught by a machine, not by me.
| Layer | What it proves | How it keeps the AI honest |
|---|---|---|
| Pest tests | The code does what it should | Encodes the intended behaviour; a regression flips a test red |
| Code coverage | Which code actually ran under test | Shows the AI the paths it forgot to test |
| Mutation testing | The tests would catch a bug | Breaks the code on purpose; a test that stays green is a real gap |
| Browser tests | The real UI and flows work | Drives an actual browser: clicks, types, asserts what renders |
| Pattern library | Each component in each state | Fixed states from props, no data to bootstrap, doubles as docs |
| Visual regression | Nothing changed that shouldn't | Screenshots flag unintended ripples across the rest of the app |
A few of these are worth slowing down on, because the why isn't obvious.
Tests encode intent. Coverage and mutation keep them honest. Here's the trap: a test suite an agent wrote can be all green and still prove nothing. It can assert nothing meaningful and pass every single time. Coverage catches the obvious version of that, code that no test even ran. Mutation testing catches the sneaky version. It breaks the code on purpose and checks that a test screams. A mutant that survives is a test that looks like it's working and isn't. Sometimes it turns up a real bug in the code while it's at it. Together they stop the agent from marking its own homework with a blank page.
The pattern library is the unlock for UI. This one is Storybook. A story is a single component rendered with a fixed set of props: empty, normal, long title, error. That one idea solves three problems at once:
- 🧩 No data to bootstrap. I don't seed a database and click through the app to reach the empty state. I describe it with props and it renders instantly.
- 📖 It's documentation. The set of stories is the catalogue of how each component is meant to look.
- 📸 It makes visual regression stable. Same props in, same pixels out. A diff only fires on a real change, not noise.
Screenshots catch the blast radius. The thing I worry about with an agent change isn't the part it meant to touch. It's the part it didn't. A visual diff across every component is the only way an accidental ripple three screens away ever shows up.
Making the PR itself easy to read
Before any of the UI review, there's the PR itself. And a PR I can't read quickly is just more friction. So the agent writes them to a fixed, plain shape: an imperative title with no feat(scope): noise, a two-line lead in plain words, emoji-anchored sections, a callout for any real decision, and the deep detail folded into collapsible blocks. Same shape every time, so I always know where to look.
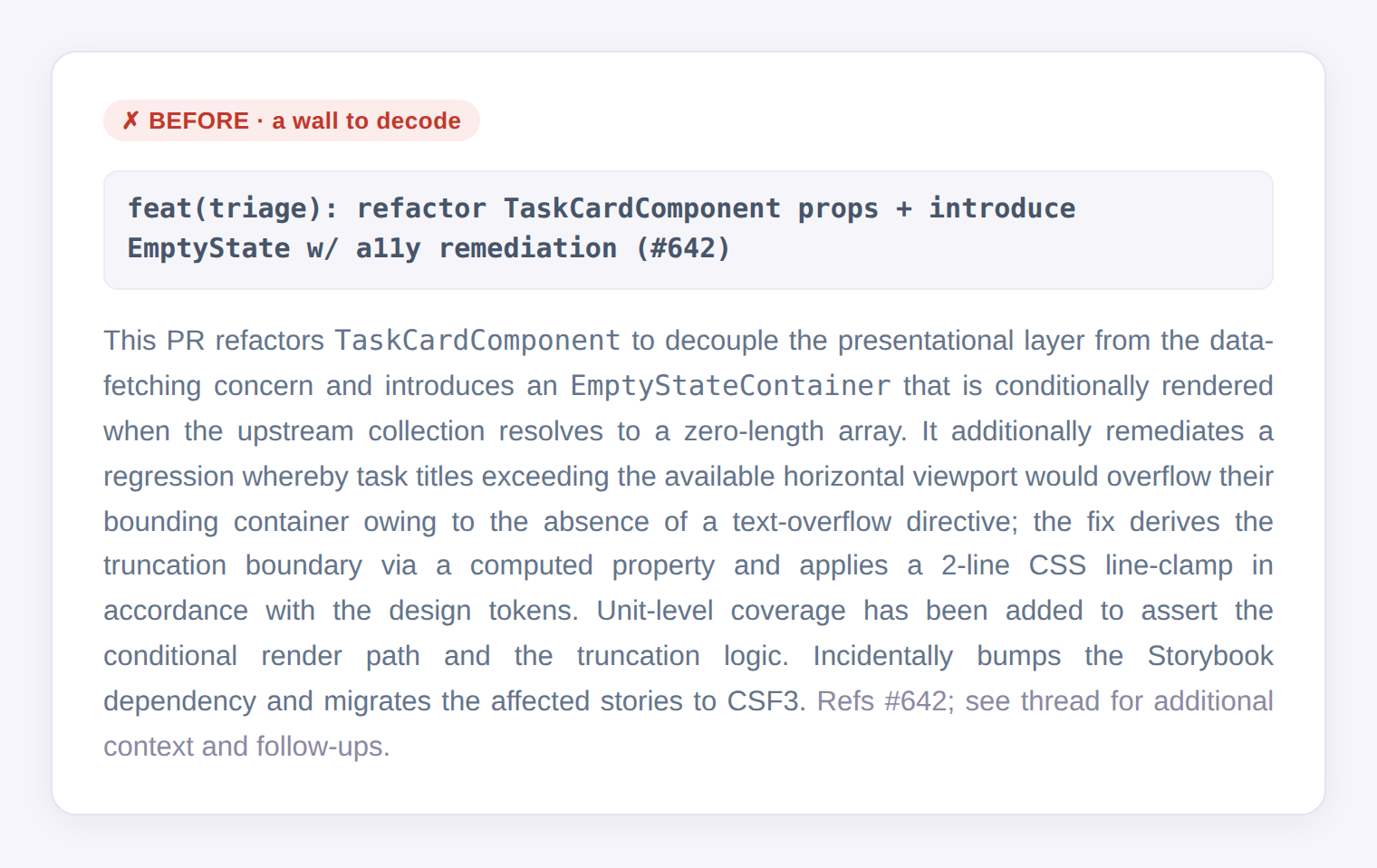
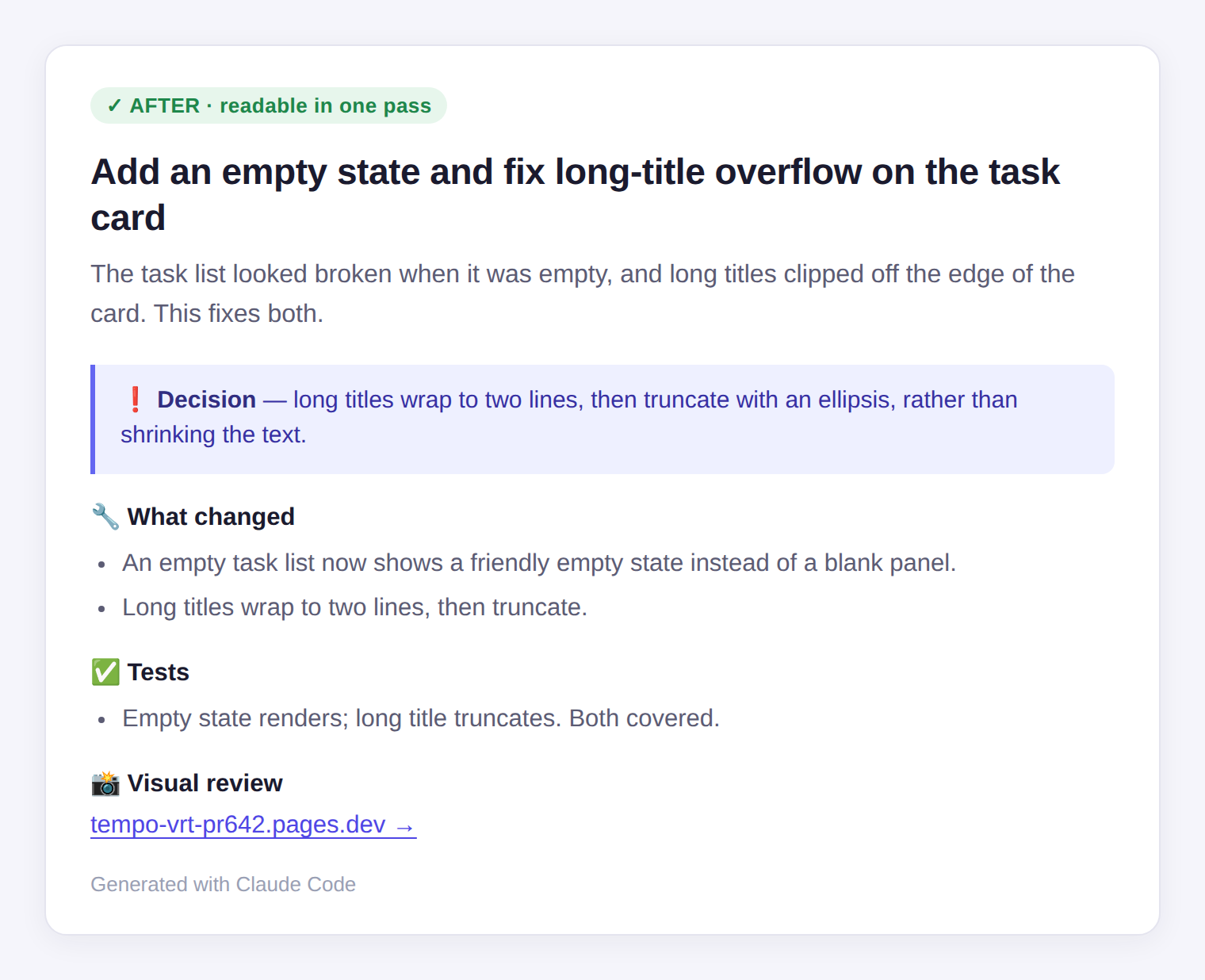
This isn't cosmetics. The first one gets skimmed. The second gets read. And a PR that gets read properly is a PR where I actually catch things. Cheap to read is the same lever as cheap to QA.
The one step that stays human
Even with all that automation, one thing stays mine. Looking at a screen and deciding it's right. No test asserts this looks good. So the goal for that last step was simple: drive its cost as close to zero as I could.
Playwright screenshots every Storybook story twice: once at my phone's width, once at a desktop one. The app is mobile-first and I review it from a phone, so a layout that only breaks at one size still has to get caught. Here's the same screen at both:
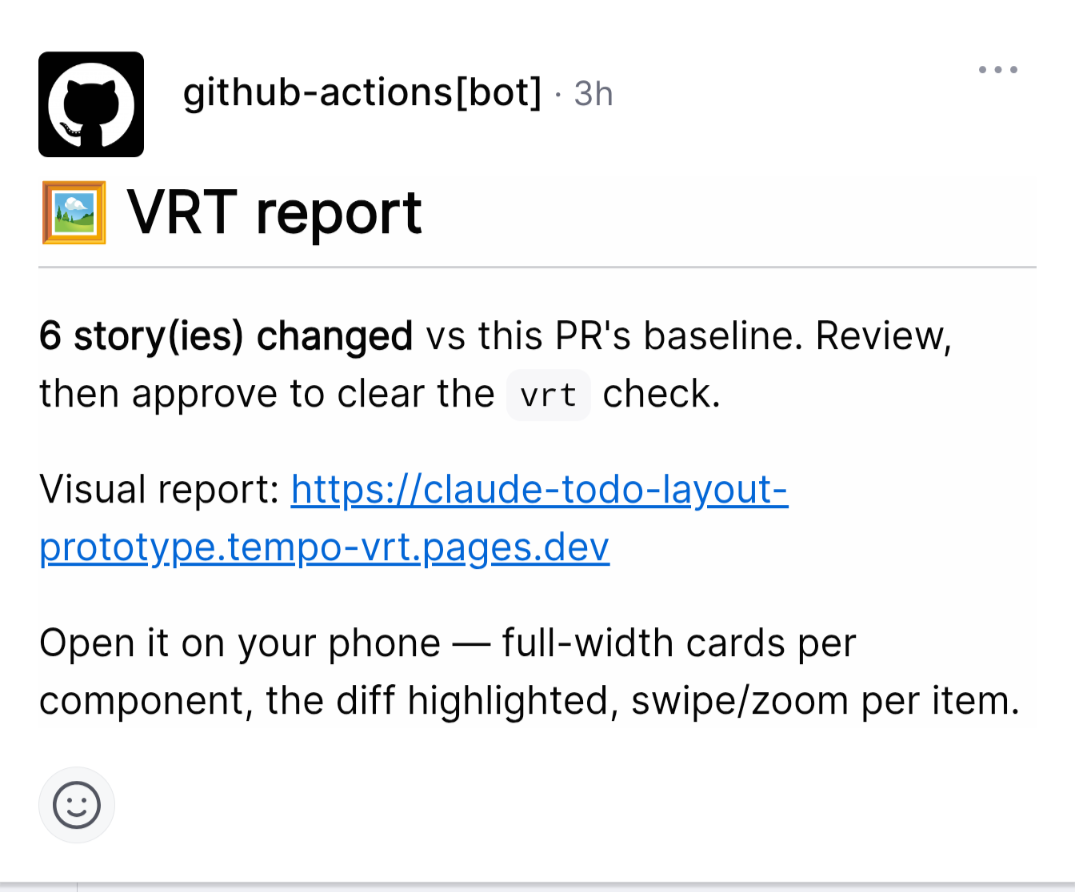
Then reg-suit does the bookkeeping that makes a diff trustworthy. It keys every snapshot to the commit that produced it, keeps them in Cloudflare R2, and picks each PR's baseline by walking git history back to the commit it branched from. Two PRs off the same point never bleed into each other's pictures. reg-cli does the pixel diff underneath, into a self-contained report. Cloudflare Pages hosts it, and a comment drops the link straight onto the PR, with a VRT label so I know a report is waiting before I even open it.
Open that link and the report is right there. Changed components float to the top with the difference highlighted; unchanged ones drop into a passed list I can ignore. Here's what it looks like. Tap any shot to blow it up:

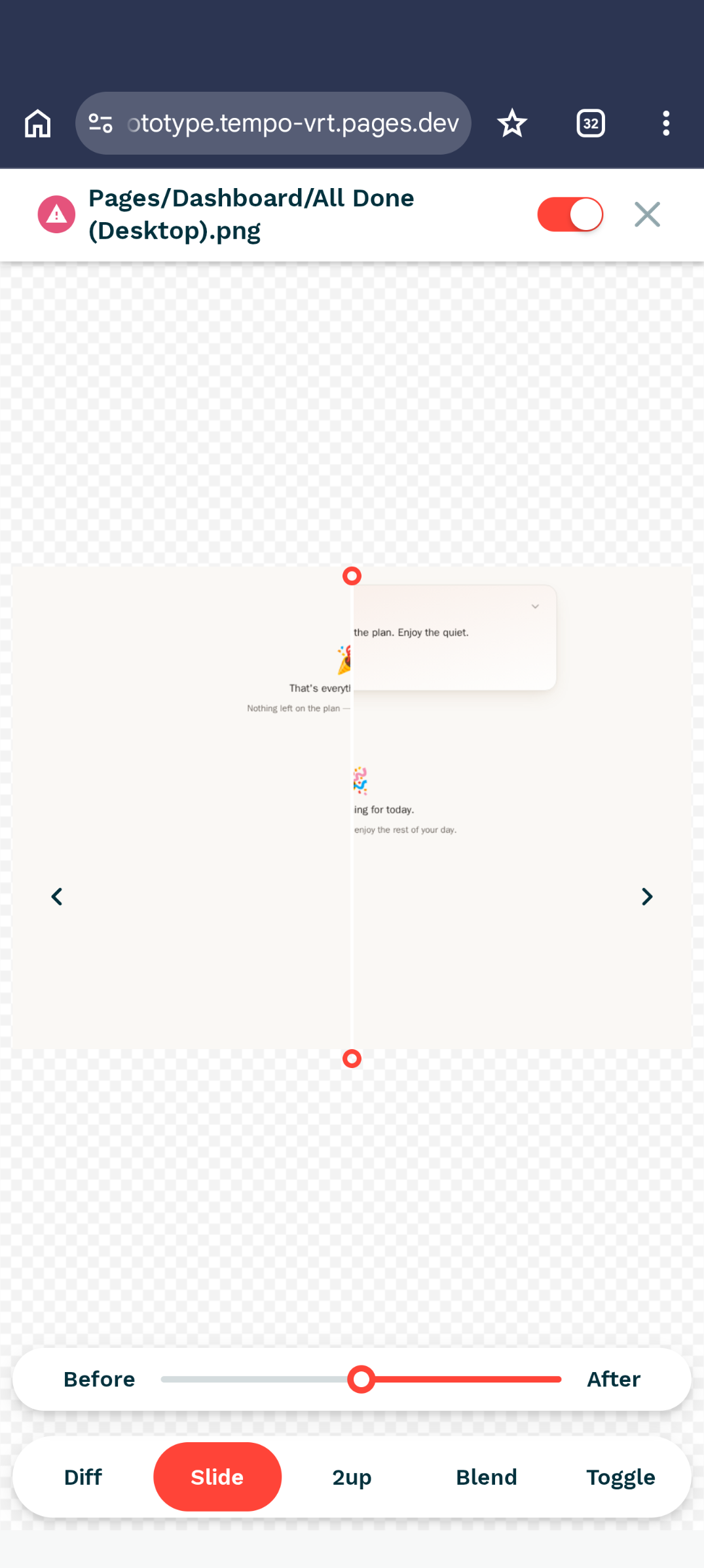
It's the thing GitHub's own image view could never give me, which is the natural place to talk about what I tried first.
The options I turned down
I didn't land here on the first try. Every obvious path broke on contact.
Just review the images in GitHub's diff
The cheapest instinct: commit the screenshots and use GitHub's image diff in the "Files changed" tab. Free, already there, no new tools.
It falls apart on a phone. The GitHub mobile app renders committed images as binary files are not rendered, so you get nothing at all. The mobile browser does a little better. It shows the two-up view, then clips the images, refuses to zoom, and ignores taps on the swipe and onion-skin modes. The data was sitting right there in the repo and I still couldn't review it from where I work.

The bot-token inline-screenshot trick
For a while I inlined screenshots straight into the PR body through a bot account, since private repos only render images uploaded as attachments. When it worked, it was lovely. Then the bot's session token would expire, roughly every fortnight, and the inline step would fail in silence. A review surface that quietly stops working is worse than one that's obviously broken. You stop trusting all of them.
Pay for a hosted visual-regression service
Chromatic, Percy and Argos all do exactly this, and their review apps work beautifully on mobile. The catch is the pricing curve. Free tiers sit around 5,000 to 7,000 snapshots a month, and this project burns through snapshots fast (every component, times every state, times every push). Past that you're looking at $100+ a month to look at pictures of your own app. That was the one thing I most wanted to avoid.
Histoire
I looked at Histoire as the Vue-native option, but its development had stalled, and I didn't want to build on a foundation that wasn't moving. Storybook had just shipped first-class Vite and Vue 3 support and is very much alive. So that's where I went.
Privacy, and a link you can try
The report sits on the public internet for convenience, but locked behind Cloudflare Access. Opening it asks for a one-time code to my email first. No one else sees screenshots of the app, and I still get a one-tap link.
Try it yourself, for free
Both halves cost nothing at this scale. Stand up Cloudflare Pages for the hosting, then put Cloudflare Access in front for the private URL: no server to run, no bill to pay. Want it wired up for you? Open the prompt below and paste it into your AI.
🪄 View the prompt (paste it into your AI)
text
Help me set up a private visual-regression report I can review from my phone, for free.
I want:
1. Screenshots of every component and page state. I use Storybook + Playwright — adapt if I tell you I use something else.
2. A diff report built in CI with reg-suit and reg-cli, with each pull request's baseline picked from the commit it branched off.
3. Hosting on Cloudflare Pages, published fresh on every pull request.
4. Privacy via Cloudflare Access in front of it: opening the report asks for a one-time email code, and only my address is allowed.
5. A comment on each PR that drops the report link, plus a label so I can see which PRs have a report waiting.
Ask me for my Cloudflare account, the email to allow, and any tokens you need. Then give me the exact CI workflow and config, and walk me through wiring up Cloudflare Pages and Access one step at a time.Owning only the glue
Add it all up and the pipeline is Storybook, Playwright, reg-suit with reg-cli underneath, and Cloudflare Pages over R2. I wrote none of them. They're stitched together by one CI workflow file and a short capture script. That split was the whole point.
The whole bill: £0
Storybook, Playwright, reg-suit and reg-cli are open source. Cloudflare Pages, R2 and Access all sit inside their free tiers at this volume. The visual-review pipeline costs nothing to run: what I spend is attention, keeping a dozen lines of glue alive, not money.
The principle has a name I keep coming back to: minimise the cost of ownership. Every line of infrastructure you write is something you own forever. You maintain it. You debug it at 11pm. You carry it when the framework underneath shifts. The four big pieces here are bought, not in money but in attention, since they're free. Someone else maintains Storybook's renderer and Cloudflare's hosting. I own only the glue, because the glue is the only part that's specific to me. When this breaks, it's a dozen lines of YAML to fix, not a diffing engine. That's also why I walked past the paid tools. Good as they are, at $100+ a month the cost just moves from maintenance to rent.
Where this is heading
The shape of it is a net that keeps getting denser. Pest proves the behaviour. Coverage and mutation prove the tests. Browser tests prove the flows. The pattern library pins the states. Visual regression catches the ripples. By the time a change reaches me, most of the ways it could have been wrong are already ruled out. What's left is one private link, one minute, from wherever I happen to be.
And because that step is cheap, I take it on every PR instead of saving it up. Which means I catch more, not less, and the bar goes up rather than sliding on the days I'm busy. The goal was never to remove the human. It's to stack enough proof underneath that the human only looks at the part that actually needs a human. The agent writes the code. The net decides whether it's any good. The one judgement left is mine, and it's the only one I want to be making.
What's next
Everything above is the net around the code. But the net is something I built too, and it's the part I now spend most of my time on: the rules, the skills, the gates an agent clears before anything reaches me. Which surfaces the one question I still can't answer with proof. When I change the harness, how do I know I made it better?
I'm increasingly sure that's the question worth obsessing over, because the harness is where the leverage is. Addy Osmani points at two public numbers that make it concrete. On Terminal Bench 2.0, one team moved a coding agent from outside the top 30 into the top 5 by changing only the harness, the same model underneath. A LangChain experiment added 13.7 points on the same benchmark by changing only the prompt, tools and middleware around a fixed model. Neither touched the model. His takeaway is the one I've come to live by:
So when an agent does something dumb, I've learned to debug the harness first. Usually it's a missing tool, a rule I wrote too loosely, a guardrail I forgot, or a context window full of junk. Most agent failures are configuration failures.
That's the encouraging part. Configuration is the thing I can fix today, with no better model required. But it cuts both ways: if the harness is the lever, I'd better know which way I'm pulling it.
Today I eyeball it. I adjust a rule, watch the next few PRs, form an impression. That's the exact trap this post is about, moved up a level: an impression isn't proof.
So the next layer is evals. Measure the harness the way the tests measure the code: does it do what I expect, and is a given change a real improvement or just a change? Garrett Lord makes the case that evals are the strategic IP that will define the next era of AI, and I think he's right. The model is rented. What you own is how you know it's working. The whole discipline fits in five words:
Set the bar at the eval, not the demo.
After that, more loops. Right now I'm in the loop on purpose: the tooling is young, so I watch it run, catch where it's wrong, and grow it by hand. That's the right place to stand while the thing is still forming. But the trajectory is the same one this whole post describes. Every layer of proof I stack lets me step further back, until more of the work runs itself and less of it waits on me. The handwork now is what buys the automation later.
One thing I will never trade for speed is quality. Using AI to build faster is not a licence to ship worse, and if anything it's the reverse: this entire net exists so the bar goes up, not down. The standard I hold the work to does not move one inch because a machine wrote the first draft.
Here's the honest constraint under both: cost. Evals mean running the harness over and over to score it. More loops mean more agent runs with nobody watching the meter. And I'm one developer on a personal project, paying for every token myself. So I can't just throw compute at it. Each step has to buy more than it costs.
Which is why the last piece is about which models, not just more of them. The pattern I'm moving toward splits the work by what it's worth: lean on the strongest reasoning model for the decisions that matter (planning, reviewing, judging), and hand the cheaper, faster models the code execution underneath. I do a version of this today with Opus as the planner, and it's solid. But Fable 5 has been on another level for me at exactly those reasoning, planning and review steps, the moments where one better decision saves ten wasted runs. Spend the expensive thinking where it changes the outcome. Buy the rest cheap.
None of this is built yet, and writing it down is how I keep myself honest about the order. The net I have today tells me whether the code is good. The next one has to tell me whether the harness is. And the day I trust that answer the way I already trust a green test, I get to step back a little further and let the machine catch a little more.
The app screenshots and the reg-viz report above are real output from the live pipeline. The three GitHub-interface sketches (the PR body, the "binary files not rendered" screen, the PR comment) are representative. And yes, this post was drafted by an agent and reviewed before publishing, which is fittingly the same arrangement it describes.